在人工智能、高性能计算和数据分析领域,数据处理的速度与效率是决定成败的关键。传统的数据处理流程中,数据需要在存储设备(如SSD)、系统内存(RAM)和图形处理器(GPU)之间进行多次搬运和复制,这个过程——即“数据移动”——常常成为整个系统的性能瓶颈,消耗大量的时间和功耗,并限制了GPU强大算力的充分发挥。
一种名为“GPU直接访问存储”或更具体地说,“GPU直连NVMe SSD”的技术架构正在兴起,旨在从根本上解决这一瓶颈,为数据处理和存储服务带来革命性的变化。
核心原理:消除中间环节
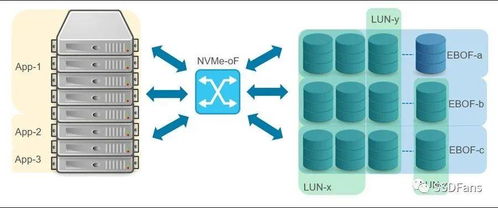
“GPU直连NVMe SSD”的核心思想,是允许GPU通过高速互联通道(如PCIe)绕过CPU和系统主内存,直接访问NVMe固态硬盘中的数据。这得益于几项关键技术的成熟:
- NVMe协议:作为专为闪存设计的协议,NVMe充分利用了PCIe总线的高带宽和低延迟特性,提供了极高的存储I/O性能。
- PCIe Peer-to-Peer (P2P):这项技术允许连接到同一PCIe总线上的设备(如GPU和NVMe SSD)直接进行数据传输,无需经过主机内存的中转。
- GPU计算生态的演进:现代GPU(如NVIDIA的DGX系统、AMD的Instinct系列及Intel的Max系列GPU)不仅在并行计算上能力超群,其内存带宽和I/O子系统也设计得异常强大,为直接处理海量数据流奠定了基础。
带来的变革性优势
这种架构为数据处理与存储服务带来了多重显著优势:
- 极致降低延迟:数据从SSD到GPU计算单元的路径被缩短到极致。对于需要频繁访问大型数据集的AI训练、推理或科学模拟应用,这意味着更快的迭代速度和实时响应能力。
- 大幅提升吞吐量:避免了通过系统内存的带宽限制,GPU可以直接以接近PCIe总线理论带宽的速度“吞食”数据,特别适合数据密集型的流处理任务。
- 解放CPU与系统内存:CPU从繁重的数据搬运任务中解脱出来,可以更专注于逻辑控制和任务调度。系统内存的压力也得到缓解,无需再为充当数据缓冲区而配置超大容量。
- 提升能效比:减少不必要的数据复制和移动,直接降低了系统的整体功耗,使每瓦特电力能产生更多的有效计算。
应用场景展望
GPU直连存储的架构将在多个前沿领域大放异彩:
- 大规模AI训练:千亿参数模型的训练需要从海量样本中不断读取数据。直连架构可以确保数据管道永不“断粮”,让GPU算力持续饱和运行。
- 高性能数据分析:在金融分析、基因组学、气候建模等领域,对TB甚至PB级数据集的实时查询与分析将成为可能。
- 边缘计算与推理:在自动驾驶、工业质检等场景中,设备需要实时处理传感器产生的高速数据流。GPU直连高速本地存储,可以实现极低延迟的决策。
- 云与超算服务:云服务商可以构建新型的数据中心服务器,将GPU算力与超高速存储更紧密地耦合,为客户提供前所未有的数据处理服务。
挑战与未来
这项技术也面临一些挑战。它对硬件拓扑(如PCIe交换和NUMA架构)、驱动程序、操作系统(需支持直接访问和内存管理)以及应用程序(需要适配新的API,如NVIDIA的GPUDirect Storage)都提出了新的要求。软件生态的成熟是广泛落地的关键。
随着CXL互联协议的普及和计算存储(Computational Storage)技术的发展,GPU、CPU与存储设备的界限将进一步模糊,可能会形成更智能、更一体化的“数据处理单元”。GPU直连NVMe SSD是迈向这个未来坚实的一步,它不仅仅是连接方式的改变,更是对以计算为中心的新型数据处理与存储服务范式的一次重要宣告。